
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- random.uniform
- 살려줘
- 맵차트
- vlookup
- mysql
- 태블로
- putty
- 정제
- 오류
- TabPy
- SQL
- Delete
- 데이터전처리
- split
- 외부접속허용
- Def
- 이전날짜제거
- safe mode 해제
- 에러
- 태블로퍼블릭
- 아나콘다
- concat
- 북마크
- Tableau
- 전처리
- 함수
- 파이썬
- Join
- D2E8DA72
- trim
- Today
- Total
무던히 하다보면 느는
[python] 집계 기본 함수 정리 (2) 본문
01 조건별 그룹 집계
grouped = employeem.groupby(['department','gender'])['salary'].mean().unstack()
grouped['gender_diff'] = grouped['Male'] - grouped['Female']
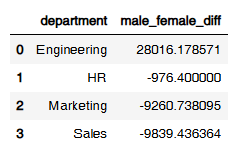
result_df = grouped[['gender_diff']].reset_index()
result_df.columns = ['department','male_female_diff']
result_dfgrouped = employee.groupby(['department', 'gender'])['salary'].mean()
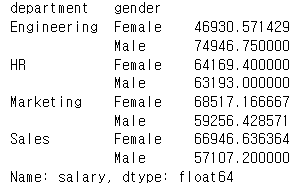
grouped = employee.groupby(['department', 'gender'])['salary'].mean().unstack()
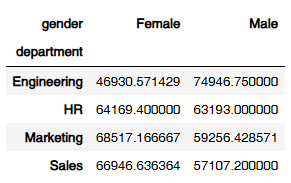
grouped = employee.groupby(['department', 'gender'])['salary'].mean().unstack()
grouped['gender_diff'] = grouped['Male'] - grouped['Female']
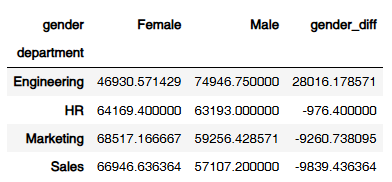
result_df = grouped[['gender_diff']].reset_index() << 멀티 인덱스 삭제
result_df.columns = ['department', 'male_female_diff']
02 사용자별 평균 대비 비율 계산
columns = ['user_id','purchase_amount']
각 사용자의 구매 금액이 전체 평균 구매 금액의 몇 %인지 계산하고, 비율(%)이라는 컬럼으로 추가한 후
상위 5명을 비율 기준으로 출력하시옹
all_avg = df['purchase_amount'].mean()
user_avg = df.groupby('user_id', as_index=False)['purchase_amount'].mean()
user_avg['비율(%)'] = round((user_avg['purchase_amount']/all_avg) *100,2)
top5_ratio = user_avg.sort_values(by='비율(%)', ascending = False).head(5)
03 사용자-월별 최대 구매액 변화 감지
columns = ["user_id", "transaction_date", "amount"]
각 사용자별로 월별 최대 결제 금액의 증가/감소 여부를 시계열 순서로 "증가", "감소", "변화 없음" 으로 구하시오.
결과는 user_id, month, amount, 변화여부 컬럼이 포함된 DataFrame으로 출력하세요.
transactions['month'] = transactions['transaction_date'].dt.to_period('M')
monthly_max = transactions.groupby(['user_id','month'], as_index=False)['amount'].max()
monthly_max['prev'] = monthly_max.groupby('user_id')['amount'].shift(1)
def classification(row):
if pd.isna(row['prev']):
return '시작'
elif row['amount'] >= row['prev']:
return '증가'
elif row['amount'] <= row['prev']:
return '감소'
else:
return '변화없옹'
monthly_max['변화여부'] = monthly_max.apply(classification, axis = 1)
monthly_maxtransactions['month'] = transactions['transaction_date'].dt.to_period('M')
monthly_max = transactions.groupby(['user_id','month'], as_index=False)['amount'].max()
monthly_max['prev'] = monthly_max.groupby('user_id')['amount'].shift(1)
def classification(row):
if pd.isna(row['prev']): # https://wikidocs.net/153206
return '시작'
elif row['amount'] >= row['prev']:
return '증가'
elif row['amount'] <= row['prev']:
return '감소'
else:
return '변화없옹'
monthly_max['변화여부'] = monthly_max.apply(classification, axis = 1)
monthly_max

https://uni2237.tistory.com/154
[pandas] Dataframe 행 위,아래로 옮기기 : shift()
pandas.DataFrame.shift() DataFrame.shift(periods=1, freq=None, axis=0, fill_value=NoDefault.no_default) Parameters) periods : int (음수 or 양수) 움직일 기간 freq : DateOffset, tseries.offsets, timedelta, or str, optional 데이터를 재정렬하
uni2237.tistory.com
04 Monthly Transactions
Write an SQL query to find for each month and country, the number of transactions and their total amount, the number of approved transactions and their total amount.
Return the result table in any order.
The query result format is in the following example.
각 월별, 나라별로 거래의 수와 총 거래량, 승인된 거래의 수와 승인된 거래량 쿼리

Pandas의 groupby() 함수는 기본적으로 NaN 값을 그룹핑에서 무시
하지만 dropna=False 옵션을 사용하면 NaN도 그룹으로 포함
transactions['month'] = transactions['trans_date'].dt.to_period('M').astype(str)
total = transactions.groupby(['month','country']).agg(
transaction_count=('id','count', dropna=False),
total_amount=('amount','sum')
)
approved = transactions[transactions['state'] == 'approved'] \
.groupby(['month','country'], dropna=False).agg(
approved_count=('id','count'),
approved_amount=('amount','sum')
)
result = total.join(approved, how='left').fillna(0) # inner
result['approved_count'] = result['approved_count'].astype(int)
result['approved_amount'] = result['approved_amount'].astype(int)
result = result.reset_index()
result = result[[
'month',
'country',
'transactions_count',
'approved_count',
'transactions_amount',
'approved_amounts']]
.agg() 함수
df.groupby(['기준컬럼']).agg(
새로운_컬럼명1 = ('원본_컬럼명', '집계함수') ,
새로운_컬럼명2 = ('원본_컬럼명', '집계함수')
)
total = transactions.groupby(['id','country'], dropna=False).agg(
total_count = ('id', 'count'),
total_amount = ('amount','sum')
)
 |
 |
★★
result = total.join(approved, how = 'left').fillna(0)
result['approved_count'] = result['approved_count'].astype(int)
result['approved_amount'] = result['approved_amount'].astype(int)
여기서 approved_* 만 int로 캐스팅하는 이유?
approved_*만 NaN이 생길 수 있기 때문. approved 거래가 없는 경우도 대비해, .fillna(0) 으로 바꾸고 int로 캐스팅함
(+) 컬럼 순서 재배치
result = result.reset_index() [[
'month',
'country',
'transactions_count',
'transactions_amount',
'approved_amount',
'approved_count'
]]
(+) 기타 unstack에 관하여..
transactions['month'] = transactions['trans_date'].dt.to_period('M')
transactions.groupby(['month','country','state'])['state'].count().unstack(fill_value=0)
grouped = transactions.groupby(['month','country','state'])['state'].count() \
.unstack(fill_value=0).reset_index()
grouped.columns.name = None
grouped = grouped.rename(columns={
'approved':'approved_count',
'declined':'declined_count'
})
transactions.groupby(['month','country','state'])['state'].count()

transactions['month'] = transactions['trans_date'].dt.to_period('M')
transactions.groupby(['month','country','state']).count().unstack(fill_value=0)
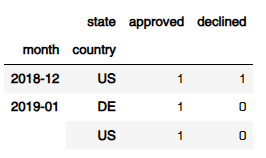
transactions.groupby(['month','country','state']).count().unstack(fill_value=0).reset_index() << 멀티인덱스 삭제
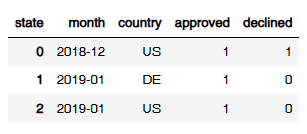
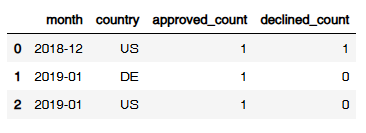
grouped.columns.name = None
grouped = grouped.rename(columns={
'approved' : 'approved_count',
'declined' : 'declied_count'
})
'코딩테스트' 카테고리의 다른 글
| [mysql] Investigating a Drop in User Engagement (0) | 2025.04.24 |
|---|---|
| [mysql] Validating A/B Test Result (0) | 2025.04.24 |
| [python] leetcode 집계함수 문제 (1) | 2025.04.18 |
| [python] 통계 관련 함수 정리 (0) | 2025.04.17 |
| [python] 집계 기본 함수 정리 (0) | 2025.04.17 |


